Reasoning about agents
Introduction
The previous chapters have shown how to compute optimal actions for agents in MDPs and POMDPs. In many practical applications, this is the goal. For example, when controlling a robot, the goal is for the robot to act optimally given its utility function. When playing the stock market or poker, the goal is make money and one might use an approach based on the POMDP agent model from the previous chapter.
In other settings, however, the goal is to learn or reason about an agent based on their behavior. For example, in social science or psychology researchers often seek to learn about people’s preferences (denoted ) and beliefs (denoted ). The relevant data (denoted ) are usually observations of human actions. In this situation, models of optimal action can be used as generative models of human actions. The generative model predicts the behavior given preferences and beliefs. That is:
Statistical inference infers the preferences and beliefs given the observed actions . That is:
This approach, using generative models of sequential decision making, has been used to learn preferences and beliefs about education, work, health, and many other topics1.
Agent models are also used as generative models in Machine Learning, under the label “Inverse Reinforcement Learning” (IRL). One motivation for learning human preferences and beliefs is to give humans helpful recommendations (e.g. for products they are likely to enjoy). A different goal is to build systems that mimic human expert performance. For some tasks, it is hard for humans to directly specify a utility/reward function that is both correct and that can be tractably optimized. An alternative is to learn the human’s utility function by watching them perform the task. Once learned, the system can use standard RL techniques to optimize the function. This has been applied to building systems to park cars, to fly helicopters, to control human-like bots in videogames, and to play table tennis2.
This chapter provides an array of illustrative examples of learning about agents from their actions. We begin with a concrete example and then provide a general formalization of the inference problem. A virtue of using WebPPL is that doing inference over our existing agent models requires very little extra code.
Learning about an agent from their actions: motivating example
Consider the MDP version of Bob’s Restaurant Choice problem. Bob is choosing between restaurants, all restaurants are open (and Bob knows this), and Bob also knows the street layout. Previously, we discussed how to compute optimal behavior given Bob’s utility function over restaurants. Now we infer Bob’s utility function given observations of the behavior in the codebox:
///fold: restaurant constants, donutSouthTrajectory
var ___ = ' ';
var DN = { name: 'Donut N' };
var DS = { name: 'Donut S' };
var V = { name: 'Veg' };
var N = { name: 'Noodle' };
var donutSouthTrajectory = [
[{"loc":[3,1],"terminateAfterAction":false,"timeLeft":11},"l"],
[{"loc":[2,1],"terminateAfterAction":false,"timeLeft":10,"previousLoc":[3,1]},"l"],
[{"loc":[1,1],"terminateAfterAction":false,"timeLeft":9,"previousLoc":[2,1]},"l"],
[{"loc":[0,1],"terminateAfterAction":false,"timeLeft":8,"previousLoc":[1,1]},"d"],
[{"loc":[0,0],"terminateAfterAction":false,"timeLeft":7,"previousLoc":[0,1],"timeAtRestaurant":0},"l"],
[{"loc":[0,0],"terminateAfterAction":true,"timeLeft":7,"previousLoc":[0,0],"timeAtRestaurant":1},"l"]
];
///
var grid = [
['#', '#', '#', '#', V , '#'],
['#', '#', '#', ___, ___, ___],
['#', '#', DN , ___, '#', ___],
['#', '#', '#', ___, '#', ___],
['#', '#', '#', ___, ___, ___],
['#', '#', '#', ___, '#', N ],
[___, ___, ___, ___, '#', '#'],
[DS , '#', '#', ___, '#', '#']
];
var world = makeGridWorldMDP({ grid, start: [3, 1] }).world;
viz.gridworld(world, { trajectory: donutSouthTrajectory });
From Bob’s actions, we infer that he probably prefers the Donut Store to the other restaurants. An alternative explanation is that Bob cares most about saving time. He might prefer Veg (the Vegetarian Cafe) but his preference is not strong enough to spend extra time getting there.
In this first example of inference, Bob’s preference for saving time is held fixed and we infer (given the actions shown above) Bob’s preference for the different restaurants. We model Bob using the MDP agent model from Chapter 3.1. We place a uniform prior over three possible utility functions for Bob: one favoring Donut, one favoring Veg and one favoring Noodle. We compute a Bayesian posterior over these utility functions given Bob’s observed behavior. Since the world is practically deterministic (with softmax parameter set high), we just compare Bob’s predicted states under each utility function to the states actually observed. To predict Bob’s states for each utility function, we use the function simulate from Chapter 3.1.
///fold: restaurant constants, donutSouthTrajectory
var ___ = ' ';
var DN = { name: 'Donut N' };
var DS = { name: 'Donut S' };
var V = { name: 'Veg' };
var N = { name: 'Noodle' };
var donutSouthTrajectory = [
[{"loc":[3,1],"terminateAfterAction":false,"timeLeft":11},"l"],
[{"loc":[2,1],"terminateAfterAction":false,"timeLeft":10,"previousLoc":[3,1]},"l"],
[{"loc":[1,1],"terminateAfterAction":false,"timeLeft":9,"previousLoc":[2,1]},"l"],
[{"loc":[0,1],"terminateAfterAction":false,"timeLeft":8,"previousLoc":[1,1]},"d"],
[{"loc":[0,0],"terminateAfterAction":false,"timeLeft":7,"previousLoc":[0,1],"timeAtRestaurant":0},"l"],
[{"loc":[0,0],"terminateAfterAction":true,"timeLeft":7,"previousLoc":[0,0],"timeAtRestaurant":1},"l"]
];
///
var grid = [
['#', '#', '#', '#', V , '#'],
['#', '#', '#', ___, ___, ___],
['#', '#', DN , ___, '#', ___],
['#', '#', '#', ___, '#', ___],
['#', '#', '#', ___, ___, ___],
['#', '#', '#', ___, '#', N ],
[___, ___, ___, ___, '#', '#'],
[DS , '#', '#', ___, '#', '#']
];
var mdp = makeGridWorldMDP({
grid,
noReverse: true,
maxTimeAtRestaurant: 2,
start: [3, 1],
totalTime: 11
});
var makeUtilityFunction = mdp.makeUtilityFunction;
var world = mdp.world;
var startState = donutSouthTrajectory[0][0];
var utilityTablePrior = function() {
var baseUtilityTable = {
'Donut S': 1,
'Donut N': 1,
'Veg': 1,
'Noodle': 1,
'timeCost': -0.04
};
return uniformDraw(
[{ table: extend(baseUtilityTable, { 'Donut N': 2, 'Donut S': 2 }),
favourite: 'donut' },
{ table: extend(baseUtilityTable, { Veg: 2 }),
favourite: 'veg' },
{ table: extend(baseUtilityTable, { Noodle: 2 }),
favourite: 'noodle' }]
);
};
var posterior = Infer({ model() {
var utilityTableAndFavourite = utilityTablePrior();
var utilityTable = utilityTableAndFavourite.table;
var favourite = utilityTableAndFavourite.favourite;
var utility = makeUtilityFunction(utilityTable);
var params = {
utility,
alpha: 2
};
var agent = makeMDPAgent(params, world);
var predictedStateAction = simulateMDP(startState, world, agent, 'stateAction');
condition(_.isEqual(donutSouthTrajectory, predictedStateAction));
return { favourite };
}});
viz(posterior);
Learning about an agent from their actions: formalization
We will now formalize the kind of inference in the previous example. We begin by considering inference over the utilities and softmax noise parameter for an MDP agent. Later on we’ll generalize to POMDP agents and to other agents.
Following Chapter 3.1 the MDP agent is defined by a utility function and softmax parameter . In order to do inference, we need to know the agent’s starting state (which might include both their location and their time horizon ). The data we condition on is a sequence of state-action pairs:
The index for the final timestep is less than or equal to the time horzion: . We abbreviate this sequence as . The joint posterior on the agent’s utilities and noise given the observed state-action sequence is:
where the likelihood function is the MDP agent model (for simplicity we omit information about the starting state). Due to the Markov Assumption for MDPs, the probability of an agent’s action in a state is independent of the agent’s previous or later actions (given and ). This allows us to rewrite the posterior as Equation (1):
The term can be rewritten as the softmax choice function (which corresponds to the function act in our MDP agent models). This equation holds for the case where we observe a sequence of actions from timestep to (with no gaps). This tutorial focuses mostly on this case. It is trivial to extend the equation to observing multiple independently drawn such sequences (as we show below). However, if there are gaps in the sequence or if we observe only the agent’s states (not the actions), then we need to marginalize over actions that were unobserved.
Examples of learning about agents in MDPs
Example: Inference from part of a sequence of actions
The expression for the joint posterior (above) shows that it is straightforward to do inference on a part of an agent’s action sequence. For example, if we know an agent had a time horizon , we can do inference from only the agent’s first few actions.
For this example we condition on the agent making a single step from to by moving left. For an agent with low noise, this already provides very strong evidence about the agent’s preferences – not much is added by seeing the agent go all the way to Donut South.
///fold: restaurant constants
var ___ = ' ';
var DN = { name: 'Donut N' };
var DS = { name: 'Donut S' };
var V = { name: 'Veg' };
var N = { name: 'Noodle' };
///
var grid = [
['#', '#', '#', '#', V , '#'],
['#', '#', '#', ___, ___, ___],
['#', '#', DN , ___, '#', ___],
['#', '#', '#', ___, '#', ___],
['#', '#', '#', ___, ___, ___],
['#', '#', '#', ___, '#', N ],
[___, ___, ___, ___, '#', '#'],
[DS , '#', '#', ___, '#', '#']
];
var world = makeGridWorldMDP({ grid }).world;
var trajectory = [
{
loc: [3, 1],
timeLeft: 11,
terminateAfterAction: false
},
{
loc: [2, 1],
timeLeft: 10,
terminateAfterAction: false
}
];
viz.gridworld(world, { trajectory });
Our approach to inference is slightly different than in the example at the start of this chapter. The approach is a direct translation of the expression for the posterior in Equation (1) above. For each observed state-action pair, we compute the likelihood of the agent (with given ) choosing that action in the state. In contrast, the simple approach above becomes intractable for long, noisy action sequences – as it will need to loop over all possible sequences.
///fold: create restaurant choice MDP
var ___ = ' ';
var DN = { name : 'Donut N' };
var DS = { name : 'Donut S' };
var V = { name : 'Veg' };
var N = { name : 'Noodle' };
var grid = [
['#', '#', '#', '#', V , '#'],
['#', '#', '#', ___, ___, ___],
['#', '#', DN , ___, '#', ___],
['#', '#', '#', ___, '#', ___],
['#', '#', '#', ___, ___, ___],
['#', '#', '#', ___, '#', N ],
[___, ___, ___, ___, '#', '#'],
[DS , '#', '#', ___, '#', '#']
];
var mdp = makeGridWorldMDP({
grid,
noReverse: true,
maxTimeAtRestaurant: 2,
start: [3, 1],
totalTime: 11
});
///
var world = mdp.world;
var makeUtilityFunction = mdp.makeUtilityFunction;
var utilityTablePrior = function(){
var baseUtilityTable = {
'Donut S': 1,
'Donut N': 1,
'Veg': 1,
'Noodle': 1,
'timeCost': -0.04
};
return uniformDraw(
[{ table: extend(baseUtilityTable, { 'Donut N': 2, 'Donut S': 2 }),
favourite: 'donut' },
{ table: extend(baseUtilityTable, { 'Veg': 2 }),
favourite: 'veg' },
{ table: extend(baseUtilityTable, { 'Noodle': 2 }),
favourite: 'noodle' }]
);
};
var observedTrajectory = [[{
loc: [3, 1],
timeLeft: 11,
terminateAfterAction: false
}, 'l']];
var posterior = Infer({ model() {
var utilityTableAndFavourite = utilityTablePrior();
var utilityTable = utilityTableAndFavourite.table;
var utility = makeUtilityFunction(utilityTable);
var favourite = utilityTableAndFavourite.favourite;
var agent = makeMDPAgent({ utility, alpha: 2 }, world);
var act = agent.act;
// For each observed state-action pair, factor on likelihood of action
map(
function(stateAction){
var state = stateAction[0];
var action = stateAction[1];
observe(act(state), action);
},
observedTrajectory);
return { favourite };
}});
viz(posterior);
Note that utility functions where Veg or Noodle are most preferred have almost the same posterior probability. Since they had the same prior, this means that we haven’t received evidence about which the agent prefers. Moreover, assuming the agent’s timeCost is negligible, then no matter where the agent above starts out on the grid, they choose Donut North or South. So we never get any information about whether they prefer the Vegetarian Cafe or Noodle Shop!
Actually, this is not quite right. If we wait long enough, the agent’s softmax noise would eventually reveal information about which was preferred. However, we still won’t be able to efficiently learn the agent’s preferences by repeatedly watching them choose from a random start point. If there is no softmax noise, then we can make the stronger claim that even in the limit of arbitrarily many repeated i.i.d. observations, the agent’s preferences are not identified by draws from this space of scenarios.
Unidentifiability is a frequent problem when inferring an agent’s beliefs or utilities from realistic datasets. First, agents with low noise reliably avoid inferior states (as in the present example) and so their actions provide little information about the relative utilities among the inferior states. Second, using richer agent models means there are more possible explanations of the same behavior. For example, agents with high softmax noise or with false beliefs might go to a restaurant even if they don’t prefer it. One general approach to the problem of unidentifiability in IRL is active learning. Instead of passively observing the agent’s actions, you select a sequence of environments that will be maximally informative about the agent’s preferences. For recent work covering both the nature of unidentifiability in IRL as well as the active learning approach, see reft:amin2016towards.
Example: Inferring The Cost of Time and Softmax Noise
The previous examples assumed that the agent’s timeCost (the negative utility of each timestep before the agent reaches a restaurant) and the softmax were known. We can modify the above example to include them in inference.
// infer_utilities_timeCost_softmax_noise
///fold: create restaurant choice MDP, donutSouthTrajectory
var ___ = ' ';
var DN = { name : 'Donut N' };
var DS = { name : 'Donut S' };
var V = { name : 'Veg' };
var N = { name : 'Noodle' };
var grid = [
['#', '#', '#', '#', V , '#'],
['#', '#', '#', ___, ___, ___],
['#', '#', DN , ___, '#', ___],
['#', '#', '#', ___, '#', ___],
['#', '#', '#', ___, ___, ___],
['#', '#', '#', ___, '#', N ],
[___, ___, ___, ___, '#', '#'],
[DS , '#', '#', ___, '#', '#']
];
var mdp = makeGridWorldMDP({
grid,
noReverse: true,
maxTimeAtRestaurant: 2,
start: [3, 1],
totalTime: 11
});
var donutSouthTrajectory = [
[{"loc":[3,1],"terminateAfterAction":false,"timeLeft":11},"l"],
[{"loc":[2,1],"terminateAfterAction":false,"timeLeft":10,"previousLoc":[3,1]},"l"],
[{"loc":[1,1],"terminateAfterAction":false,"timeLeft":9,"previousLoc":[2,1]},"l"],
[{"loc":[0,1],"terminateAfterAction":false,"timeLeft":8,"previousLoc":[1,1]},"d"],
[{"loc":[0,0],"terminateAfterAction":false,"timeLeft":7,"previousLoc":[0,1],"timeAtRestaurant":0},"l"],
[{"loc":[0,0],"terminateAfterAction":true,"timeLeft":7,"previousLoc":[0,0],"timeAtRestaurant":1},"l"]
];
var vegDirectTrajectory = [
[{"loc":[3,1],"terminateAfterAction":false,"timeLeft":11},"u"],
[{"loc":[3,2],"terminateAfterAction":false,"timeLeft":10,"previousLoc":[3,1]},"u"],
[{"loc":[3,3],"terminateAfterAction":false,"timeLeft":9,"previousLoc":[3,2]},"u"],
[{"loc":[3,4],"terminateAfterAction":false,"timeLeft":8,"previousLoc":[3,3]},"u"],
[{"loc":[3,5],"terminateAfterAction":false,"timeLeft":7,"previousLoc":[3,4]},"u"],
[{"loc":[3,6],"terminateAfterAction":false,"timeLeft":6,"previousLoc":[3,5]},"r"],
[{"loc":[4,6],"terminateAfterAction":false,"timeLeft":5,"previousLoc":[3,6]},"u"],
[{"loc":[4,7],"terminateAfterAction":false,"timeLeft":4,"previousLoc":[4,6],"timeAtRestaurant":0},"l"],
[{"loc":[4,7],"terminateAfterAction":true,"timeLeft":4,"previousLoc":[4,7],"timeAtRestaurant":1},"l"]
];
///
var world = mdp.world;
var makeUtilityFunction = mdp.makeUtilityFunction;
// Priors
var utilityTablePrior = function() {
var foodValues = [0, 1, 2];
var timeCostValues = [-0.1, -0.3, -0.6];
var donut = uniformDraw(foodValues);
return {
'Donut N': donut,
'Donut S': donut,
'Veg': uniformDraw(foodValues),
'Noodle': uniformDraw(foodValues),
'timeCost': uniformDraw(timeCostValues)
};
};
var alphaPrior = function(){
return uniformDraw([.1, 1, 10, 100]);
};
// Condition on observed trajectory
var posterior = function(observedTrajectory){
return Infer({ model() {
var utilityTable = utilityTablePrior();
var alpha = alphaPrior();
var params = {
utility: makeUtilityFunction(utilityTable),
alpha
};
var agent = makeMDPAgent(params, world);
var act = agent.act;
// For each observed state-action pair, factor on likelihood of action
map(
function(stateAction){
var state = stateAction[0];
var action = stateAction[1]
observe(act(state), action);
},
observedTrajectory);
// Compute whether Donut is preferred to Veg and Noodle
var donut = utilityTable['Donut N'];
var donutFavorite = (
donut > utilityTable.Veg &&
donut > utilityTable.Noodle);
return {
donutFavorite,
alpha: alpha.toString(),
timeCost: utilityTable.timeCost.toString()
};
}});
};
print('Prior:');
var prior = posterior([]);
viz.marginals(prior);
print('Conditioning on one action:');
var posterior = posterior(donutSouthTrajectory.slice(0, 1));
viz.marginals(posterior);
The posterior shows that taking a step towards Donut South can now be explained in terms of a high timeCost. If the agent has a low value for , this step to the left is fairly likely even if the agent prefers Noodle or Veg. So including softmax noise in the inference makes inferences about other parameters closer to the prior.
Exercise: Suppose the agent is observed going all the way to Veg. What would the posteriors on and
timeCostlook like? Check your answer by conditioning on the state-action sequencevegDirectTrajectory. You will need to modify other parts of the codebox above to make this work.
As we noted previously, it is simple to extend our approach to inference to conditioning on multiple sequences of actions. Consider the two sequences below:
///fold: make restaurant choice MDP, naiveTrajectory, donutSouthTrajectory
var ___ = ' ';
var DN = { name : 'Donut N' };
var DS = { name : 'Donut S' };
var V = { name : 'Veg' };
var N = { name : 'Noodle' };
var grid = [
['#', '#', '#', '#', V , '#'],
['#', '#', '#', ___, ___, ___],
['#', '#', DN , ___, '#', ___],
['#', '#', '#', ___, '#', ___],
['#', '#', '#', ___, ___, ___],
['#', '#', '#', ___, '#', N ],
[___, ___, ___, ___, '#', '#'],
[DS , '#', '#', ___, '#', '#']
];
var mdp = makeGridWorldMDP({
grid,
noReverse: true,
maxTimeAtRestaurant: 2,
start: [3, 1],
totalTime: 11
});
var naiveTrajectory = [
[{"loc":[3,1],"terminateAfterAction":false,"timeLeft":11},"u"],
[{"loc":[3,2],"terminateAfterAction":false,"timeLeft":10,"previousLoc":[3,1]},"u"],
[{"loc":[3,3],"terminateAfterAction":false,"timeLeft":9,"previousLoc":[3,2]},"u"],
[{"loc":[3,4],"terminateAfterAction":false,"timeLeft":8,"previousLoc":[3,3]},"u"],
[{"loc":[3,5],"terminateAfterAction":false,"timeLeft":7,"previousLoc":[3,4]},"l"],
[{"loc":[2,5],"terminateAfterAction":false,"timeLeft":6,"previousLoc":[3,5],"timeAtRestaurant":0},"l"],
[{"loc":[2,5],"terminateAfterAction":true,"timeLeft":6,"previousLoc":[2,5],"timeAtRestaurant":1},"l"]
];
var donutSouthTrajectory = [
[{"loc":[3,1],"terminateAfterAction":false,"timeLeft":11},"l"],
[{"loc":[2,1],"terminateAfterAction":false,"timeLeft":10,"previousLoc":[3,1]},"l"],
[{"loc":[1,1],"terminateAfterAction":false,"timeLeft":9,"previousLoc":[2,1]},"l"],
[{"loc":[0,1],"terminateAfterAction":false,"timeLeft":8,"previousLoc":[1,1]},"d"],
[{"loc":[0,0],"terminateAfterAction":false,"timeLeft":7,"previousLoc":[0,1],"timeAtRestaurant":0},"l"],
[{"loc":[0,0],"terminateAfterAction":true,"timeLeft":7,"previousLoc":[0,0],"timeAtRestaurant":1},"l"]
];
///
var world = mdp.world;;
map(function(trajectory) { viz.gridworld(world, { trajectory }); },
[naiveTrajectory, donutSouthTrajectory]);
To perform inference, we just condition on both sequences. (We use concatenation but we could have taken the union of all state-action pairs).
///fold: World and agent are exactly as above
var ___ = ' ';
var DN = { name : 'Donut N' };
var DS = { name : 'Donut S' };
var V = { name : 'Veg' };
var N = { name : 'Noodle' };
var grid = [
['#', '#', '#', '#', V , '#'],
['#', '#', '#', ___, ___, ___],
['#', '#', DN , ___, '#', ___],
['#', '#', '#', ___, '#', ___],
['#', '#', '#', ___, ___, ___],
['#', '#', '#', ___, '#', N ],
[___, ___, ___, ___, '#', '#'],
[DS , '#', '#', ___, '#', '#']
];
var mdp = makeGridWorldMDP({
grid,
noReverse: true,
maxTimeAtRestaurant: 2,
start: [3, 1],
totalTime: 11
});
var donutSouthTrajectory = [
[{"loc":[3,1],"terminateAfterAction":false,"timeLeft":11},"l"],
[{"loc":[2,1],"terminateAfterAction":false,"timeLeft":10,"previousLoc":[3,1]},"l"],
[{"loc":[1,1],"terminateAfterAction":false,"timeLeft":9,"previousLoc":[2,1]},"l"],
[{"loc":[0,1],"terminateAfterAction":false,"timeLeft":8,"previousLoc":[1,1]},"d"],
[{"loc":[0,0],"terminateAfterAction":false,"timeLeft":7,"previousLoc":[0,1],"timeAtRestaurant":0},"l"],
[{"loc":[0,0],"terminateAfterAction":true,"timeLeft":7,"previousLoc":[0,0],"timeAtRestaurant":1},"l"]
];
var naiveTrajectory = [
[{"loc":[3,1],"terminateAfterAction":false,"timeLeft":11},"u"],
[{"loc":[3,2],"terminateAfterAction":false,"timeLeft":10,"previousLoc":[3,1]},"u"],
[{"loc":[3,3],"terminateAfterAction":false,"timeLeft":9,"previousLoc":[3,2]},"u"],
[{"loc":[3,4],"terminateAfterAction":false,"timeLeft":8,"previousLoc":[3,3]},"u"],
[{"loc":[3,5],"terminateAfterAction":false,"timeLeft":7,"previousLoc":[3,4]},"l"],
[{"loc":[2,5],"terminateAfterAction":false,"timeLeft":6,"previousLoc":[3,5],"timeAtRestaurant":0},"l"],
[{"loc":[2,5],"terminateAfterAction":true,"timeLeft":6,"previousLoc":[2,5],"timeAtRestaurant":1},"l"]
];
var world = mdp.world;
var makeUtilityFunction = mdp.makeUtilityFunction;
// Priors
var utilityTablePrior = function() {
var foodValues = [0, 1, 2];
var timeCostValues = [-0.1, -0.3, -0.6];
var donut = uniformDraw(foodValues);
return {
'Donut N': donut,
'Donut S': donut,
'Veg': uniformDraw(foodValues),
'Noodle': uniformDraw(foodValues),
'timeCost': uniformDraw(timeCostValues)
};
};
var alphaPrior = function(){
return uniformDraw([.1, 1, 10, 100]);
};
// Condition on observed trajectory
var posterior = function(observedTrajectory){
return Infer({ model() {
var utilityTable = utilityTablePrior();
var alpha = alphaPrior();
var params = {
utility: makeUtilityFunction(utilityTable),
alpha
};
var agent = makeMDPAgent(params, world);
var act = agent.act;
// For each observed state-action pair, factor on likelihood of action
map(
function(stateAction){
var state = stateAction[0];
var action = stateAction[1]
observe(act(state), action);
},
observedTrajectory);
// Compute whether Donut is preferred to Veg and Noodle
var donut = utilityTable['Donut N'];
var donutFavorite = (
donut > utilityTable.Veg &&
donut > utilityTable.Noodle);
return {
donutFavorite,
alpha: alpha.toString(),
timeCost: utilityTable.timeCost.toString()
};
}});
};
///
print('Prior:');
var prior = posterior([]);
viz.marginals(prior);
print('Posterior');
var posterior = posterior(naiveTrajectory.concat(donutSouthTrajectory));
viz.marginals(posterior);
Learning about agents in POMDPs
Formalization
We can extend our approach to inference to deal with agents that solve POMDPs. One approach to inference is simply to generate full state-action sequences and compare them to the observed data. As we mentioned above, this approach becomes intractable in cases where noise (in transitions and actions) is high and sequences are long.
Instead, we extend the approach in Equation (1) above. The first thing to notice is that Equation (1) has to be amended for POMDPs. In an MDP, actions are conditionally independent given the agent’s parameters and and the state. For any pair of actions and and state :
In a POMDP, actions are only rendered conditionally independent if we also condition on the agent’s belief. So Equation (1) can only be extended to the case where we know the agent’s belief at each timestep. This will be realistic in some applications and not others. It depends on whether the agent’s observations are part of the data that is conditioned on. If so, the agent’s belief can be computed at each timestep (assuming the agent’s initial belief is known). If not, we have to marginalize over the possible observations, making for a more complex inference computation.
Here is the extension of Equation (1) to the POMDP case, where we assume access to the agent’s observations. Our goal is to compute a posterior on the parameters of the agent. These include and as before but also the agent’s initial belief .
We observe a sequence of state-observation-action triples:
The index for the final timestep is at most the time horzion: . The joint posterior on the agent’s utilities and noise given the observed sequence is:
To produce a factorized form of this posterior analogous to Equation (1), we compute the sequence of agent beliefs. This is given by the recursive Bayesian belief update described in Chapter 3.3:
The posterior can thus be written as Equation (2):
Application: Bandits
To learn the preferences and beliefs of a POMDP agent we translate Equation (2) into WebPPL. In a later chapter, we apply this to the Restaurant Choice problem. Here we focus on the Bandit problems introduced in the previous chapter.
In the Bandit problems there is an unknown mapping from arms to non-numeric prizes (or distributions on such prizes) and the agent has preferences over these prizes. The agent tries out arms to discover the mapping and exploits the most promising arms. In the inverse problem, we get to observe the agent’s actions. Unlike the agent, we already know the mapping from arms to prizes. However, we don’t know the agent’s preferences or the agent’s prior about the mapping3.
Often the agent’s choices admit of multiple explanations. Recall the deterministic example in the previous chapter when (according to the agent’s belief) arm0 had the prize “chocolate” and arm1 had either “champagne” or “nothing” (see also Figure 2 below). Suppose we observe the agent chosing arm0 on the first of five trials. If we don’t know the agent’s utilities or beliefs, then this choice could be explained by either:
(1). the agent’s preference for chocolate over champagne, or
(2). the agent’s belief that arm1 is very likely (e.g. 95%) to yield the “nothing” prize deterministically
Given this choice by the agent, we won’t be able to identify which of (1) and (2) is true because exploration becomes less valuable every trial (and there’s only 5 trials total).
The codeboxes below implements this example. The translation of Equation (2) is in the function factorSequence. This function iterates through the observed state-observation-action triples, updating the agent’s belief at each timestep. It interleaves conditioning on an action (via factor) with computing the sequence of belief functions . The variable names correspond as follows:
-
is
initialBelief(an argument tofactorSequence) -
is
state -
is
nextBelief -
is
observedAction
var inferBeliefsAndPreferences = function(baseAgentParams, priorPrizeToUtility,
priorInitialBelief, bandit,
observedSequence) {
return Infer({ model() {
// 1. Sample utilities
var prizeToUtility = (priorPrizeToUtility ? sample(priorPrizeToUtility)
: undefined);
// 2. Sample beliefs
var initialBelief = sample(priorInitialBelief);
// 3. Construct agent given utilities and beliefs
var newAgentParams = extend(baseAgentParams, { priorBelief: initialBelief });
var agent = makeBanditAgent(newAgentParams, bandit, 'belief', prizeToUtility);
var agentAct = agent.act;
var agentUpdateBelief = agent.updateBelief;
// 4. Condition on observations
var factorSequence = function(currentBelief, previousAction, timeIndex){
if (timeIndex < observedSequence.length) {
var state = observedSequence[timeIndex].state;
var observation = observedSequence[timeIndex].observation;
var nextBelief = agentUpdateBelief(currentBelief, observation, previousAction);
var nextActionDist = agentAct(nextBelief);
var observedAction = observedSequence[timeIndex].action;
factor(nextActionDist.score(observedAction));
factorSequence(nextBelief, observedAction, timeIndex + 1);
}
};
factorSequence(initialBelief,'noAction', 0);
return {
prizeToUtility,
priorBelief: initialBelief
};
}});
};
We start with a very simple example. The agent is observed pulling arm1 five times. The agent’s prior is known and assigns equal weight to arm1 yielding “champagne” and to it yielding “nothing”. The true prize for arm1 is “champagne” (see Figure 1).
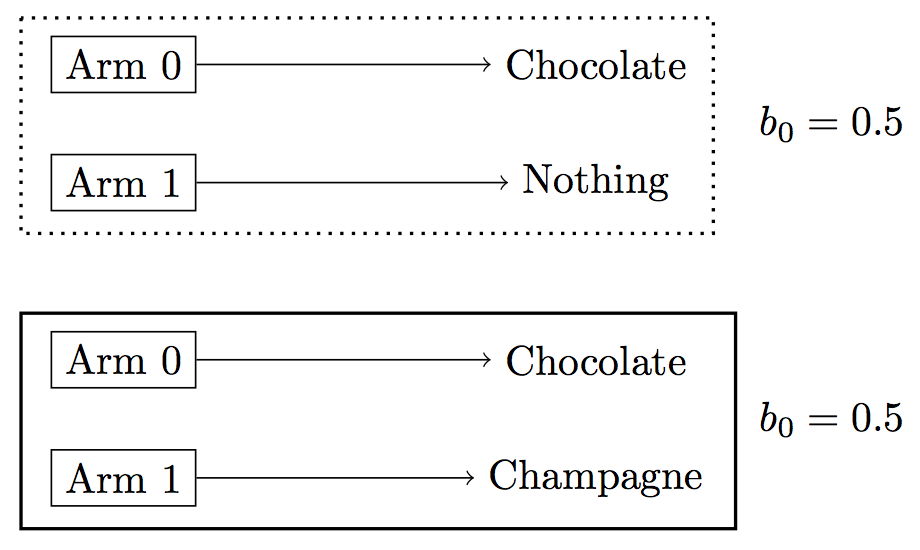
Figure 1: Bandit problem where agent’s prior is known. (The true state has the bold outline).
From the observation, it’s obvious that the agent prefers champagne. This is what we infer below:
///fold: inferBeliefsAndPreferences, getMarginal
var inferBeliefsAndPreferences = function(baseAgentParams, priorPrizeToUtility,
priorInitialBelief, bandit,
observedSequence) {
return Infer({ model() {
// 1. Sample utilities
var prizeToUtility = (priorPrizeToUtility ? sample(priorPrizeToUtility)
: undefined);
// 2. Sample beliefs
var initialBelief = sample(priorInitialBelief);
// 3. Construct agent given utilities and beliefs
var newAgentParams = extend(baseAgentParams, { priorBelief: initialBelief });
var agent = makeBanditAgent(newAgentParams, bandit, 'belief', prizeToUtility);
var agentAct = agent.act;
var agentUpdateBelief = agent.updateBelief;
// 4. Condition on observations
var factorSequence = function(currentBelief, previousAction, timeIndex){
if (timeIndex < observedSequence.length) {
var state = observedSequence[timeIndex].state;
var observation = observedSequence[timeIndex].observation;
var nextBelief = agentUpdateBelief(currentBelief, observation, previousAction);
var nextActionDist = agentAct(nextBelief);
var observedAction = observedSequence[timeIndex].action;
factor(nextActionDist.score(observedAction));
factorSequence(nextBelief, observedAction, timeIndex + 1);
}
};
factorSequence(initialBelief,'noAction', 0);
return {
prizeToUtility,
priorBelief: initialBelief
};
}});
};
var getMarginal = function(dist, key){
return Infer({ model() {
return sample(dist)[key];
}});
};
///
// true prizes for arms
var trueArmToPrizeDist = {
0: Delta({ v: 'chocolate' }),
1: Delta({ v: 'champagne' })
};
var bandit = makeBanditPOMDP({
armToPrizeDist: trueArmToPrizeDist,
numberOfArms: 2,
numberOfTrials: 5
});
// simpleAgent always pulls arm 1
var simpleAgent = makePOMDPAgent({
act: function(belief){
return Infer({ model() { return 1; }});
},
updateBelief: function(belief){ return belief; },
params: { priorBelief: Delta({ v: bandit.startState }) }
}, bandit.world);
var observedSequence = simulatePOMDP(bandit.startState, bandit.world, simpleAgent,
'stateObservationAction');
// Priors for inference
// We know agent's prior, which is that either arm1 yields
// nothing or it yields champagne.
var priorInitialBelief = Delta({ v: Infer({ model() {
var armToPrizeDist = uniformDraw([
trueArmToPrizeDist,
extend(trueArmToPrizeDist, { 1: Delta({ v: 'nothing' }) })]);
return makeBanditStartState(5, armToPrizeDist);
}})});
// Agent either prefers chocolate or champagne.
var likesChampagne = {
nothing: 0,
champagne: 5,
chocolate: 3
};
var likesChocolate = {
nothing: 0,
champagne: 3,
chocolate: 5
};
var priorPrizeToUtility = Categorical({
vs: [likesChampagne, likesChocolate],
ps: [0.5, 0.5]
});
var baseParams = { alpha: 1000 };
var posterior = inferBeliefsAndPreferences(baseParams, priorPrizeToUtility,
priorInitialBelief, bandit,
observedSequence);
print("After observing agent choose arm1, what are agent's utilities?");
print('Posterior on agent utilities:');
viz.table(getMarginal(posterior, 'prizeToUtility'));
In the codebox above, the agent’s preferences are identified by the observations. This won’t hold for the next example, which we introduced previously. The agent’s utilities for prizes are still unknown and now the agent’s prior is also unknown. Either the agent is “informed” and knows the truth that arm1 yields “champagne”. Or the agent is misinformed and believes arm1 is likely to yield “nothing”. These two possibilities are depicted in Figure 2.
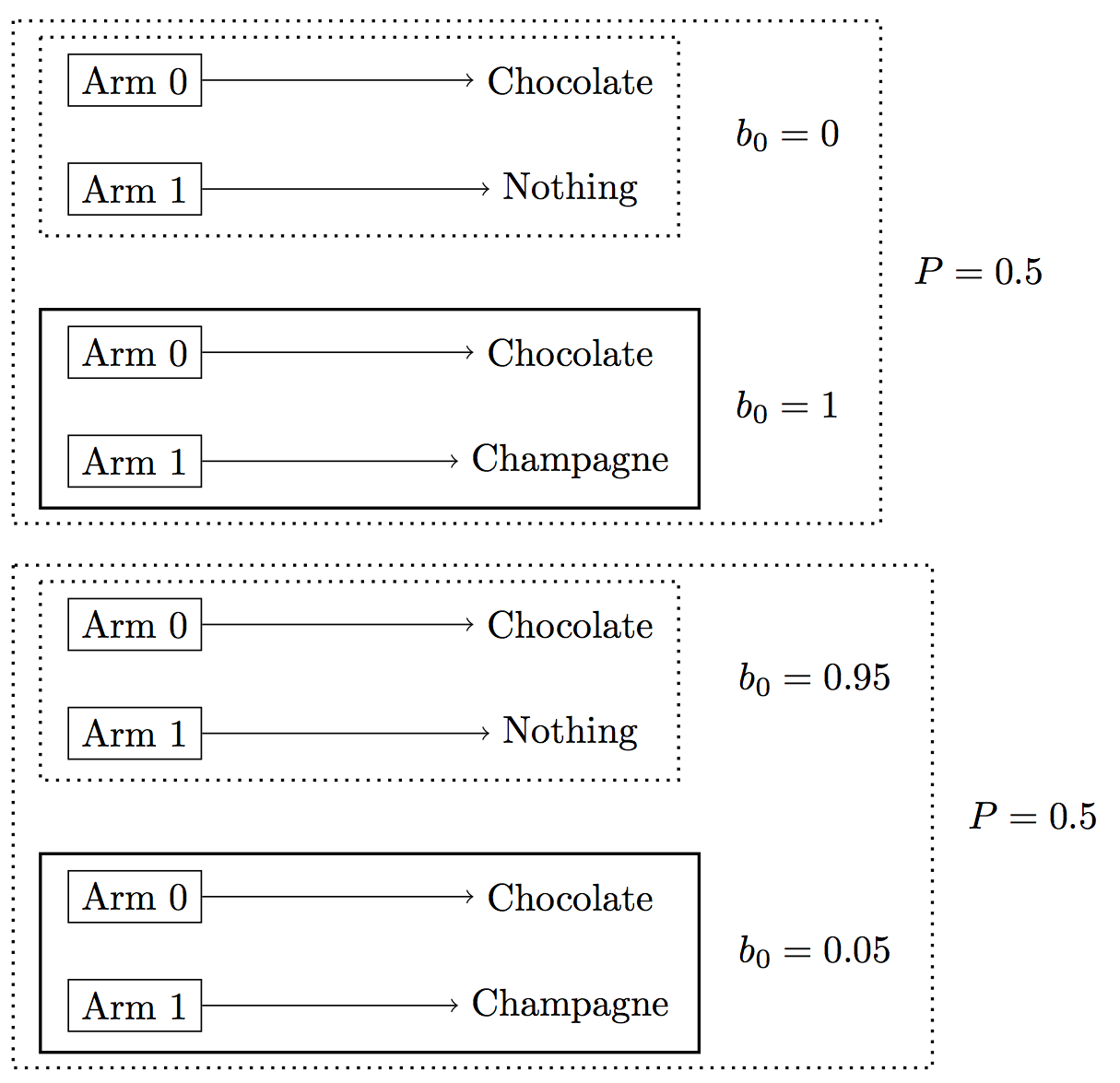
Figure 2: Bandit where agent’s prior is unknown. The two large boxes depict the prior on the agent’s initial belief. Each possibility for the agent’s initial belief has probability 0.5.
We observe the agent’s first action, which is pulling arm0. Our inference approach is the same as above:
///fold:
var inferBeliefsAndPreferences = function(baseAgentParams, priorPrizeToUtility,
priorInitialBelief, bandit,
observedSequence) {
return Infer({ model() {
// 1. Sample utilities
var prizeToUtility = (priorPrizeToUtility ? sample(priorPrizeToUtility)
: undefined);
// 2. Sample beliefs
var initialBelief = sample(priorInitialBelief);
// 3. Construct agent given utilities and beliefs
var newAgentParams = extend(baseAgentParams, { priorBelief: initialBelief });
var agent = makeBanditAgent(newAgentParams, bandit, 'belief', prizeToUtility);
var agentAct = agent.act;
var agentUpdateBelief = agent.updateBelief;
// 4. Condition on observations
var factorSequence = function(currentBelief, previousAction, timeIndex){
if (timeIndex < observedSequence.length) {
var state = observedSequence[timeIndex].state;
var observation = observedSequence[timeIndex].observation;
var nextBelief = agentUpdateBelief(currentBelief, observation, previousAction);
var nextActionDist = agentAct(nextBelief);
var observedAction = observedSequence[timeIndex].action;
factor(nextActionDist.score(observedAction));
factorSequence(nextBelief, observedAction, timeIndex + 1);
}
};
factorSequence(initialBelief,'noAction', 0);
return {
prizeToUtility,
priorBelief: initialBelief
};
}});
};
///
var trueArmToPrizeDist = {
0: Delta({ v: 'chocolate' }),
1: Delta({ v: 'champagne' })
};
var bandit = makeBanditPOMDP({
numberOfArms: 2,
armToPrizeDist: trueArmToPrizeDist,
numberOfTrials: 5
});
var simpleAgent = makePOMDPAgent({
// simpleAgent always pulls arm 0
act: function(belief){
return Infer({ model() { return 0; }});
},
updateBelief: function(belief){ return belief; },
params: { priorBelief: Delta({ v: bandit.startState }) }
}, bandit.world);
var observedSequence = simulatePOMDP(bandit.startState, bandit.world, simpleAgent,
'stateObservationAction');
// Agent either knows that arm1 has prize "champagne"
// or agent thinks prize is probably "nothing"
var informedPrior = Delta({ v: bandit.startState });
var noChampagnePrior = Infer({ model() {
var armToPrizeDist = categorical(
[0.05, 0.95],
[trueArmToPrizeDist,
extend(trueArmToPrizeDist, { 1: Delta({ v: 'nothing' }) })]);
return makeBanditStartState(5, armToPrizeDist);
}});
var priorInitialBelief = Categorical({
vs: [informedPrior, noChampagnePrior],
ps: [0.5, 0.5]
});
// We are still uncertain about whether agent prefers chocolate or champagne
var likesChampagne = {
nothing: 0,
champagne: 5,
chocolate: 3
};
var likesChocolate = {
nothing: 0,
champagne: 3,
chocolate: 5
};
var priorPrizeToUtility = Categorical({
ps: [0.5, 0.5],
vs: [likesChampagne, likesChocolate]
});
var baseParams = {alpha: 1000};
var posterior = inferBeliefsAndPreferences(baseParams, priorPrizeToUtility,
priorInitialBelief, bandit,
observedSequence);
var utilityBeliefPosterior = Infer({ model() {
var utilityBelief = sample(posterior);
var chocolateUtility = utilityBelief.prizeToUtility.chocolate;
var likesChocolate = chocolateUtility > 3;
var isInformed = utilityBelief.priorBelief.support().length === 1;
return { likesChocolate, isInformed };
}});
viz.table(utilityBeliefPosterior);
Exploration is more valuable if there are more Bandit trials in total. If we observe the agent choosing the arm they already know about (arm0) then we get stronger inferences about their preference for chocolate over champagne as the total trials increases.
// TODO simplify the code here or merge with previous example.
///fold:
var inferBeliefsAndPreferences = function(baseAgentParams, priorPrizeToUtility,
priorInitialBelief, bandit,
observedSequence) {
return Infer({ model() {
// 1. Sample utilities
var prizeToUtility = (priorPrizeToUtility ? sample(priorPrizeToUtility)
: undefined);
// 2. Sample beliefs
var initialBelief = sample(priorInitialBelief);
// 3. Construct agent given utilities and beliefs
var newAgentParams = extend(baseAgentParams, { priorBelief: initialBelief });
var agent = makeBanditAgent(newAgentParams, bandit, 'belief', prizeToUtility);
var agentAct = agent.act;
var agentUpdateBelief = agent.updateBelief;
// 4. Condition on observations
var factorSequence = function(currentBelief, previousAction, timeIndex){
if (timeIndex < observedSequence.length) {
var state = observedSequence[timeIndex].state;
var observation = observedSequence[timeIndex].observation;
var nextBelief = agentUpdateBelief(currentBelief, observation, previousAction);
var nextActionDist = agentAct(nextBelief);
var observedAction = observedSequence[timeIndex].action;
factor(nextActionDist.score(observedAction));
factorSequence(nextBelief, observedAction, timeIndex + 1);
}
};
factorSequence(initialBelief,'noAction', 0);
return {
prizeToUtility,
priorBelief: initialBelief
};
}});
};
///
var probLikesChocolate = function(numberOfTrials){
var trueArmToPrizeDist = {
0: Delta({ v: 'chocolate' }),
1: Delta({ v: 'champagne' })
};
var bandit = makeBanditPOMDP({
numberOfArms: 2,
armToPrizeDist: trueArmToPrizeDist,
numberOfTrials
});
var simpleAgent = makePOMDPAgent({
// simpleAgent always pulls arm 0
act: function(belief){
return Infer({ model() { return 0; }});
},
updateBelief: function(belief){ return belief; },
params: { priorBelief: Delta({ v: bandit.startState }) }
}, bandit.world);
var observedSequence = simulatePOMDP(bandit.startState, bandit.world, simpleAgent,
'stateObservationAction');
var baseParams = { alpha: 100 };
var noChampagnePrior = Infer({ model() {
var armToPrizeDist = (
flip(0.2) ?
trueArmToPrizeDist :
extend(trueArmToPrizeDist, { 1: Delta({ v: 'nothing' }) }));
return makeBanditStartState(numberOfTrials, armToPrizeDist);
}});
var informedPrior = Delta({ v: bandit.startState });
var priorInitialBelief = Categorical({
vs: [noChampagnePrior, informedPrior],
ps: [0.5, 0.5],
});
var likesChampagne = {
nothing: 0,
champagne: 5,
chocolate: 3
};
var likesChocolate = {
nothing: 0,
champagne: 3,
chocolate: 5
};
var priorPrizeToUtility = Categorical({
vs: [likesChampagne, likesChocolate],
ps: [0.5, 0.5],
});
var posterior = inferBeliefsAndPreferences(baseParams, priorPrizeToUtility,
priorInitialBelief, bandit,
observedSequence);
var likesChocInformed = {
prizeToUtility: likesChocolate,
priorBelief: informedPrior
};
var probLikesChocInformed = Math.exp(posterior.score(likesChocInformed));
var likesChocNoChampagne = {
prizeToUtility: likesChocolate,
priorBelief: noChampagnePrior
};
var probLikesChocNoChampagne = Math.exp(posterior.score(likesChocNoChampagne));
return probLikesChocInformed + probLikesChocNoChampagne;
};
var lifetimes = [5, 6, 7, 8, 9];
var probsLikesChoc = map(probLikesChocolate, lifetimes);
print('Probability of liking chocolate for lifetimes ' + lifetimes + '\n'
+ probsLikesChoc);
viz.bar(lifetimes, probsLikesChoc);
This example of inferring an agent’s utilities from a Bandit problem may seem contrived. However, there are practical problems that have a similar structure. Consider a domain where sources (arms) produce a stream of content, with each piece of content having a category (prizes). At each timestep, a human is observed choosing a source. The human has uncertainty about the stochastic mapping from sources to categories. Our goal is to infer the human’s beliefs about the sources and their preferences over categories. The sources could be blogs or feeds that tag posts using the same set of tags. Alternatively, the sources could be channels for TV shows or songs. In this kind of application, the same issue of identifiability arises. An agent may choose a source either because they know it produces content in the best categories or because they have a strong prior belief that it does.
In the next chapter, we start looking at agents with cognitive bounds and biases.
Footnotes
-
The approach in economics closest to the one we outline here (with models of action based on sequential decision making) is called “Structural Estimation”. Some particular examples are reft:aguirregabiria2010dynamic and reft:darden2010smoking. A related piece of work in AI or computational social science is reft:ermon2014learning. ↩
-
The relevant papers on applications of IRL: parking cars in reft:abbeel2008apprenticeship, flying helicopters in reft:abbeel2010autonomous, controlling videogame bots in reft:lee2010learning, and table tennis in reft:muelling2014learning. ↩
-
If we did not know the mapping from arms to prizes, the inference problem would not change fundamentally. We get information about this mapping by observing the prizes the agent receives when pulling different arms. ↩