Time inconsistency I
Introduction
Time inconsistency is part of everyday human experience. In the night you wish to rise early; in the morning you prefer to sleep in. There is an inconsistency between what you prefer your future self to do and what your future self prefers to do. Forseeing this inconsistency, you take actions in the night to bind your future self to get up. These range from setting an alarm clock to arranging for someone drag you out of bed.
This pattern is not limited to attempts to rise early. People make failed resolutions to attend a gym regularly. Students procrastinate on writing papers, planning to start early but delaying until the last minute. Empirical studies have highlighted the practical import of time inconsistency both to completing online courses refp:patterson2015can and to watching highbrow movies refp:milkman2009highbrow. Time inconsistency has been used to explain not just quotidian laziness but also addiction, procrastination, and impulsive behavior, as well an array of “pre-commitment” behaviors refp:ainslie2001breakdown.
Lab experiments of time inconsistency often use simple quantitative questions such as:
Question: Would you prefer to get $100 after 30 days or $110 after 31 days?
Most people prefer the $110. But a significant proportion of people reverse their earlier preference once the 30th day comes around and they contemplate getting $100 immediately. How can this time consistency be captured by a formal model?
Time inconsistency due to hyperbolic discounting
This chapter models time inconsistency as resulting from hyperbolic discounting. The idea is that humans prefer receiving the same rewards sooner rather than later and the discount function describing this quantitatively is a hyperbola. Before describing the hyperbolic model, we provide some background on time discounting and incorporate it into our previous agent models.
Exponential discounting for optimal agents
The examples of decision problems in previous chapters have a known, finite time horizon. Yet there are practical decision problems that are better modeled as having an unbounded or infinite time horizon. For example, if someone tries to travel home after a vacation, there is no obvious time limit for their task. The same holds for a person saving or investing for the long-term.
Generalizing the previous agent models to the unbounded case faces a difficulty. The infinite summed expected utility of an action will (generally) not converge. The standard solution is to model the agent as maximizing the discounted expected utility, where the discount function is exponential. This makes the infinite sums converge and results in an agent model that is analytically and computationally tractable. Aside from mathematical convenience, exponential discounting might also be an accurate model of the “time preference” of certain rational agents1. Exponential discounting represents a (consistent) preference for good things happening sooner rather than later2.
What are the effects of exponential discounting? We return to the deterministic Bandit problem from Chapter III.3 (see Figure 1). Suppose a person decides every year where to go on a skiing vacation. There is a fixed set of options {Tahoe, Chile, Switzerland} and a finite time horizon3. The person discounts exponentially and so they prefer a good vacation now to an even better one in the future. This means they are less likely to explore, since exploration takes time to pay off.
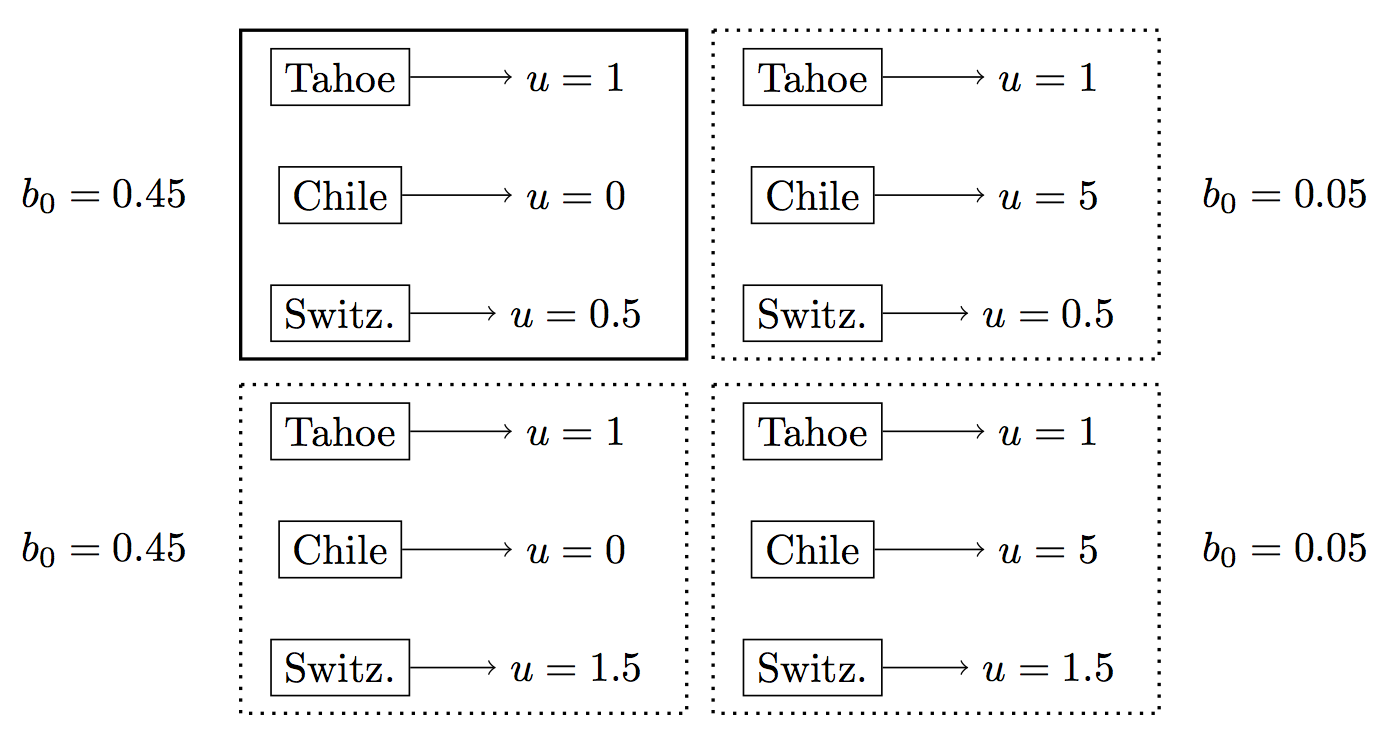
Figure 1: Deterministic Bandit problem. The agent tries different arms/destinations and receives rewards. The reward for Tahoe is known but Chile and Switzerland are both unknown. The actual best option is Tahoe.
///fold:
var baseParams = {
noDelays: false,
discount: 0,
sophisticatedOrNaive: 'naive'
};
var armToPlace = function(arm){
return {
0: "Tahoe",
1: "Chile",
2: "Switzerland"
}[arm];
};
var display = function(trajectory) {
return map(armToPlace, most(trajectory));
};
///
// Arms are skiing destinations:
// 0: "Tahoe", 1: "Chile", 2: "Switzerland"
// Actual utility for each destination
var trueArmToPrizeDist = {
0: Delta({ v: 1 }),
1: Delta({ v: 0 }),
2: Delta({ v: 0.5 })
};
// Constuct Bandit world
var numberOfTrials = 10;
var bandit = makeBanditPOMDP({
numberOfArms: 3,
armToPrizeDist: trueArmToPrizeDist,
numberOfTrials,
numericalPrizes: true
});
var world = bandit.world;
var start = bandit.startState;
// Agent prior for utility of each destination
var priorBelief = Infer({ model() {
var armToPrizeDist = {
// Tahoe has known utility 1:
0: Delta({ v: 1 }),
// Chile has high variance:
1: categorical([0.9, 0.1],
[Delta({ v: 0 }), Delta({ v: 5 })]),
// Switzerland has high expected value:
2: uniformDraw([Delta({ v: 0.5 }), Delta({ v: 1.5 })])
};
return makeBanditStartState(numberOfTrials, armToPrizeDist);
}});
var discountFunction = function(delay) {
return Math.pow(0.5, delay);
};
var exponentialParams = extend(baseParams, { discountFunction, priorBelief });
var exponentialAgent = makeBanditAgent(exponentialParams, bandit,
'beliefDelay');
var exponentialTrajectory = simulatePOMDP(start, world, exponentialAgent, 'actions');
var optimalParams = extend(baseParams, { priorBelief });
var optimalAgent = makeBanditAgent(optimalParams, bandit, 'belief');
var optimalTrajectory = simulatePOMDP(start, world, optimalAgent, 'actions');
print('exponential discounting trajectory: ' + display(exponentialTrajectory));
print('\noptimal trajectory: ' + display(optimalTrajectory));
Discounting and time inconsistency
Exponential discounting is typically thought of as a relative time preference. A fixed reward will be discounted by a factor of \(\delta^{-30}\) if received on Day 30 rather than Day 0. On Day 30, the same reward is discounted by \(\delta^{-30}\) if received on Day 60 and not at all if received on Day 30. This relative time preference is “inconsistent” in a superficial sense. With \(\delta=0.95\) per day (and linear utility in money), $100 after 30 days is worth $21 and $110 at 31 days is worth $22. Yet when the 30th day arrives, they are worth $100 and $105 respectively4! The key point is that whereas these magnitudes have changed, the ratios stay fixed. Indeed, the ratio between a pair of outcomes stays fixed regardless of when the exponential discounter evaluates them. In summary: while a discounting agent evaluates two prospects in the future as worth little compared to similar near-term prospects, the agent agrees with their future self about which of the two future prospects is better.
Any smooth discount function other than an exponential will result in preferences that reverse over time refp:strotz1955myopia. So it’s not so suprising that untutored humans should be subject to such reversals5. Various functional forms for human discounting have been explored in the literature. We describe the hyperbolic discounting model refp:ainslie2001breakdown because it is simple and well-studied. Other functional form can be substituted into our models.
Hyperbolic and exponential discounting curves are illustrated in Figure 2. We plot the discount factor \(D\) as a function of time \(t\) in days, with constants \(\delta\) and \(k\) controlling the slope of the function. In this example, each constant is set to 2. The exponential is:
\[D=\frac{1}{\delta^t}\]The hyperbolic function is:
\[D=\frac{1}{1+kt}\]The crucial difference between the curves is that the hyperbola is initially steep and then becomes almost flat, while the exponential continues to be steep. This means that exponential discounting is time consistent and hyperbolic discounting is not.
var delays = _.range(7);
var expDiscount = function(delay) {
return Math.pow(0.5, delay);
};
var hypDiscount = function(delay) {
return 1.0 / (1 + 2*delay);
};
var makeExpDatum = function(delay){
return {
delay,
discountFactor: expDiscount(delay),
discountType: 'Exponential discounting: 1/2^t'
};
};
var makeHypDatum = function(delay){
return {
delay,
discountFactor: hypDiscount(delay),
discountType: 'Hyperbolic discounting: 1/(1 + 2t)'
};
};
var expData = map(makeExpDatum, delays);
var hypData = map(makeHypDatum, delays);
viz.line(expData.concat(hypData), { groupBy: 'discountType' });
Figure 2: Graph comparing exponential and hyperbolic discount curves.
Exercise: We return to our running example but with slightly different numbers. The agent chooses between receiving $100 after 4 days or $110 after 5 days. The goal is to compute the preferences over each option for both exponential and hyperbolic discounters, using the discount curves shown in Figure 2. Compute the following:
- The discounted utility of the $100 and $110 rewards relative to Day 0 (i.e. how much the agent values each option when the rewards are 4 or 5 days away).
- The discounted utility of the $100 and $110 rewards relative to Day 4 (i.e. how much each option is valued when the rewards are 0 or 1 day away).
Time inconsistency and sequential decision problems
We have shown that hyperbolic discounters have different preferences over the $100 and $110 depending on when they make the evaluation. This conflict in preferences leads to complexities in planning that don’t occur in the optimal (PO)MDP agents which either discount exponentially or do not discount at all.
Consider the example in the exercise <a href=#exercise>above</a> and imagine you have time inconsistent preferences. On Day 0, you write down your preference but on Day 4 you’ll be free to change your mind. If you know your future self would choose the $100 immediately, you’d pay a small cost now to pre-commit your future self. However, if you believe your future self will share your current preferences, you won’t pay this cost (and so you’ll end up taking the $100). This illustrates a key distinction. Time inconsistent agents can be “Naive” or “Sophisticated”:
-
Naive agent: assumes his future self shares his current time preference. For example, a Naive hyperbolic discounter assumes his far future self has a nearly flat discount curve (rather than the “steep then flat” discount curve he actually has).
-
Sophisticated agent: has the correct model of his future self’s time preference. A Sophisticated hyperbolic discounter has a nearly flat discount curve for the far future but is aware that his future self does not share this discount curve.
Both kinds of agents evaluate rewards differently at different times. To distinguish a hyperbolic discounter’s current and future selves, we refer to the agent acting at time \(t_i\) as the \(t_i\)-agent. A Sophisticated agent, unlike a Naive agent, has an accurate model of his future selves. The Sophisticated \(t_0\)-agent predicts the actions of the \(t\)-agents (for \(t>t_0\)) that would conflict with his preferences. To prevent these actions, the \(t_0\)-agent tries to take actions that pre-commit the future agents to outcomes the \(t_0\)-agent prefers6.
Naive and Sophisticated Agents: Gridworld Example
Before describing our formal model and implementation of Naive and Sophisticated hyperbolic discounters, we illustrate their contrasting behavior using the Restaurant Choice example. We use the MDP version, where the agent has full knowledge of the locations of restaurants and of which restaurants are open. Recall the problem setup:
Restaurant Choice: Bob is looking for a place to eat. His decision problem is to take a sequence of actions such that (a) he eats at a restaurant he likes and (b) he does not spend too much time walking. The restaurant options are: the Donut Store, the Vegetarian Salad Bar, and the Noodle Shop. The Donut Store is a chain with two local branches. We assume each branch has identical utility for Bob. We abbreviate the restaurant names as “Donut South”, “Donut North”, “Veg” and “Noodle”.
The only difference from previous versions of Restaurant Choice is that restaurants now have two utilities. On entering a restaurant, the agent first receives the immediate reward (i.e. how good the food tastes) and at the next timestep receives the delayed reward (i.e. how good the person feels after eating it).
Exercise: Run the codebox immediately below. Think of ways in which Naive and Sophisticated hyperbolic discounters with identical preferences (i.e. identical utilities for each restaurant) might differ for this decision problem.
///fold: restaurant choice MDP
var ___ = ' ';
var DN = { name : 'Donut N' };
var DS = { name : 'Donut S' };
var V = { name : 'Veg' };
var N = { name : 'Noodle' };
var grid = [
['#', '#', '#', '#', V , '#'],
['#', '#', '#', ___, ___, ___],
['#', '#', DN , ___, '#', ___],
['#', '#', '#', ___, '#', ___],
['#', '#', '#', ___, ___, ___],
['#', '#', '#', ___, '#', N ],
[___, ___, ___, ___, '#', '#'],
[DS , '#', '#', ___, '#', '#']
];
var mdp = makeGridWorldMDP({
grid,
noReverse: true,
maxTimeAtRestaurant: 2,
start: [3, 1],
totalTime: 11
});
///
viz.gridworld(mdp.world, { trajectory: [mdp.startState] });
The next two codeboxes show the behavior of two hyperbolic discounters. Each agent has the same preferences and discount function. They differ only in that the first is Naive and the second is Sophisticated.
///fold: restaurant choice MDP, naiveTrajectory
var ___ = ' ';
var DN = { name : 'Donut N' };
var DS = { name : 'Donut S' };
var V = { name : 'Veg' };
var N = { name : 'Noodle' };
var grid = [
['#', '#', '#', '#', V , '#'],
['#', '#', '#', ___, ___, ___],
['#', '#', DN , ___, '#', ___],
['#', '#', '#', ___, '#', ___],
['#', '#', '#', ___, ___, ___],
['#', '#', '#', ___, '#', N ],
[___, ___, ___, ___, '#', '#'],
[DS , '#', '#', ___, '#', '#']
];
var mdp = makeGridWorldMDP({
grid,
noReverse: true,
maxTimeAtRestaurant: 2,
start: [3, 1],
totalTime: 11
});
var naiveTrajectory = [
[{"loc":[3,1],"terminateAfterAction":false,"timeLeft":11},"u"],
[{"loc":[3,2],"terminateAfterAction":false,"timeLeft":10,"previousLoc":[3,1]},"u"],
[{"loc":[3,3],"terminateAfterAction":false,"timeLeft":9,"previousLoc":[3,2]},"u"],
[{"loc":[3,4],"terminateAfterAction":false,"timeLeft":8,"previousLoc":[3,3]},"u"],
[{"loc":[3,5],"terminateAfterAction":false,"timeLeft":7,"previousLoc":[3,4]},"l"],
[{"loc":[2,5],"terminateAfterAction":false,"timeLeft":6,"previousLoc":[3,5],"timeAtRestaurant":0},"l"],
[{"loc":[2,5],"terminateAfterAction":true,"timeLeft":6,"previousLoc":[2,5],"timeAtRestaurant":1},"l"]
];
///
viz.gridworld(mdp.world, { trajectory: naiveTrajectory });
///fold: restaurant choice MDP, sophisticatedTrajectory
var ___ = ' ';
var DN = { name : 'Donut N' };
var DS = { name : 'Donut S' };
var V = { name : 'Veg' };
var N = { name : 'Noodle' };
var grid = [
['#', '#', '#', '#', V , '#'],
['#', '#', '#', ___, ___, ___],
['#', '#', DN , ___, '#', ___],
['#', '#', '#', ___, '#', ___],
['#', '#', '#', ___, ___, ___],
['#', '#', '#', ___, '#', N ],
[___, ___, ___, ___, '#', '#'],
[DS , '#', '#', ___, '#', '#']
];
var mdp = makeGridWorldMDP({
grid,
noReverse: true,
maxTimeAtRestaurant: 2,
start: [3, 1],
totalTime: 11
});
var sophisticatedTrajectory = [
[{"loc":[3,1],"terminateAfterAction":false,"timeLeft":11},"u"],
[{"loc":[3,2],"terminateAfterAction":false,"timeLeft":10,"previousLoc":[3,1]},"u"],
[{"loc":[3,3],"terminateAfterAction":false,"timeLeft":9,"previousLoc":[3,2]},"r"],
[{"loc":[4,3],"terminateAfterAction":false,"timeLeft":8,"previousLoc":[3,3]},"r"],
[{"loc":[5,3],"terminateAfterAction":false,"timeLeft":7,"previousLoc":[4,3]},"u"],
[{"loc":[5,4],"terminateAfterAction":false,"timeLeft":6,"previousLoc":[5,3]},"u"],
[{"loc":[5,5],"terminateAfterAction":false,"timeLeft":5,"previousLoc":[5,4]},"u"],
[{"loc":[5,6],"terminateAfterAction":false,"timeLeft":4,"previousLoc":[5,5]},"l"],
[{"loc":[4,6],"terminateAfterAction":false,"timeLeft":3,"previousLoc":[5,6]},"u"],
[{"loc":[4,7],"terminateAfterAction":false,"timeLeft":2,"previousLoc":[4,6],"timeAtRestaurant":0},"l"],
[{"loc":[4,7],"terminateAfterAction":true,"timeLeft":2,"previousLoc":[4,7],"timeAtRestaurant":1},"l"]
];
///
viz.gridworld(mdp.world, { trajectory: sophisticatedTrajectory });
Exercise: (Try this exercise before reading further). Your goal is to do preference inference from the observed actions in the codeboxes above (using only a pen and paper). The discount function is the hyperbola \(D=1/(1+kt)\), where \(t\) is the time from the present, \(D\) is the discount factor (to be multiplied by the utility) and \(k\) is a positive constant. Find a single setting for the utilities and discount function that produce the behavior in both the codeboxes above. This includes utilities for the restaurants (both immediate and delayed) and for the
timeCost(the negative utility for each additional step walked), as well as the discount constant \(k\). Assume there is no softmax noise.
The Naive agent goes to Donut North, even though Donut South (which has identical utility) is closer to the agent’s starting point. One possible explanation is that the Naive agent has a higher utility for Veg but gets “tempted” by Donut North on their way to Veg7.
The Sophisticated agent can accurately model what it would do if it ended up in location [3,5] (adjacent to Donut North). So it avoids temptation by taking the long, inefficient route to Veg.
In this simple example, the Naive and Sophisticated agents each take paths that optimal time-consistent MDP agents (without softmax noise) would never take. So this is an example where a bias leads to a systematic deviation from optimality and behavior that is not predicted by an optimal model. In Chapter 5.3 we explore inference of preferences for time inconsistent agents.
Next chapter: Time inconsistency II
Footnotes
-
People care about a range of things: e.g. the food they eat daily, their careers, their families, the progress of science, the preservation of the earth’s environment. Many have argued that humans have a time preference. So models that infer human preferences from behavior should be able to represent this time preference. ↩
-
There are arguments that exponential discounting is the uniquely rational mode of discounting for agents with time preference. The seminal paper by refp:strotz1955myopia proves that, “in the continuous time setting, the only discount function such that the optimal policy doesn’t vary in time is exponential discounting”. In the discrete-time setting, refp:lattimore2014general prove the same result, as well as discussing optimal strategies for sophisticated time-inconsistent agents. ↩
-
As noted above, exponential discounting is usually combined with an unbounded time horizon. However, if a human makes a series of decisions over a long time scale, then it makes sense to include their time preference. For this particular example, imagine the person is looking for the best skiing or sports facilities and doesn’t care about variety. There could be a known finite time horizon because at some age they are too old for adventurous skiing. ↩
-
One can think of exponential discounting in a non-relative way by choosing a fixed staring time in the past (e.g. the agent’s birth) and discounting everything relative to that. This results in an agent with a preference to travel back in time to get higher rewards! ↩
-
Without computational aids, human representations of discrete and continuous quantities (including durations in time and dollar values) are systematically inaccurate. See refp:dehaene2011number. ↩
-
As has been pointed out previously, there is a kind of “inter-generational” conflict between agent’s future selves. If pre-commitment actions are available at time \(t_0\), the \(t_0\)-agent does better in expectation if it is Sophisticated rather than Naive. Equivalently, the \(t_0\)-agent’s future selves will do better if the agent is Naive. ↩
-
At the start, no restaurants can be reached quickly and so the agent’s discount function is nearly flat when evaluating each one of them. This makes Veg look most attractive (given its higher overall utility). But going to Veg means getting closer to Donut North, which becomes more attractive than Veg once the agent is close to it (because of the discount function). Taking an inefficient path – one that is dominated by another path – is typical of time-inconsistent agents. ↩